Table of Contents
- Introduction: Why magic states at all?
- Clifford gates, stabilizer states and the need for magic
- Magic state distillation: The basic idea
- A concrete example: The Bravyi–Kitaev 5-qubit protocol
- Resource overheads and the distillation factory picture
- From distillation to cultivation: Changing the mindset
- Why cultivation? Practical motivations
- Anatomy of a cultivation protocol
- A simple quantitative picture
- Hybrid architectures: Cultivation feeding distillation
- Experimental progress
- Concluding thoughts
- Key references
Visualizing the growth and nurturing of magic states across a quantum error-correcting code lattice.
Introduction: Why Magic States at All?
In this blog-style article I want to walk through why I care about magic state distillation and why, more recently, I have become equally fascinated by magic state cultivation. I will start from the basic problem of fault-tolerant universality, then move to a concrete distillation example, and finally discuss how cultivation changes the story from the perspective of space-time overhead and architectural realism. My goal is not to give a full formal review, but rather to provide an intuitive yet technically honest narrative that one could share with colleagues over coffee.
The setting I always have in mind is a large-scale surface code or color code architecture, where I know how to do Clifford gates in a relatively clean, transversal or lattice-surgery-based way, but where non-Clifford gates such as the \(T\) gate stubbornly refuse to be implemented fault-tolerantly at low cost. In that setting, magic states are my resource for non-Clifford power, and the central engineering question becomes: how do I obtain a supply of high-fidelity magic states using only noisy hardware-level operations and fault-tolerant Clifford gadgets? [1][4]
Clifford Gates, Stabilizer States and the Need for Magic
Let me briefly recall the stabilizer picture, because it is the conceptual backbone behind magic state distillation. The Clifford group on \(n\) qubits is the normalizer of the \(n\)-qubit Pauli group: conjugation by any Clifford maps Pauli operators to Pauli operators. Famous examples are the Hadamard gate \(H\), the phase gate \(S\) and the CNOT gate, and together they generate the Clifford group. When I restrict myself to Clifford unitaries, preparations of Pauli eigenstates, and Pauli measurements, my dynamics stay within the stabilizer formalism and are classically efficiently simulable.
From a computational complexity perspective this means that Clifford-only quantum computation does not buy me an asymptotic advantage over classical computers. To break out of this stabilizer world I need at least one non-Clifford ingredient, for example the \(T\) gate
which together with Clifford gates generates a dense subset of \(SU(2)\). In a fault-tolerant architecture based on two-dimensional topological codes, transversal implementations of \(T\) are typically forbidden by Eastin–Knill-type no-go theorems, which is why the usual strategy is to teleport \(T\) into the computation using an ancilla state[4].
The usual choice of ancilla is the so-called \(T\)-type magic state
where \(\ket{+} = (\ket{0} + \ket{1})/\sqrt{2}\). Given access to ideal Clifford operations and a supply of perfect \(\ket{T}\) states, I can implement logical \(T\) gates, Toffoli gates via \(\ket{CCZ}\) magic, and ultimately achieve universal quantum computation [2][4]. The remaining question is: how do I obtain those high-fidelity magic states from noisy hardware?
Magic State Distillation: The Basic Idea
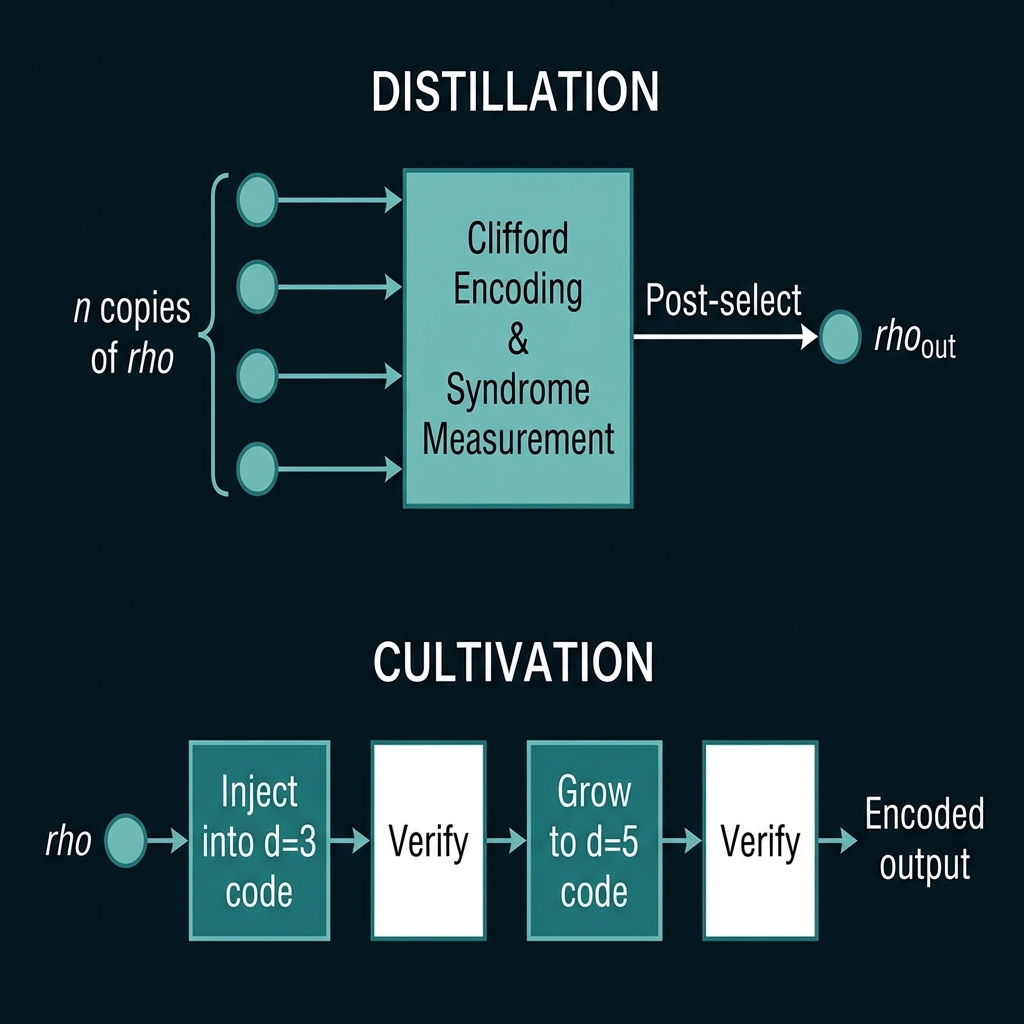
Magic state distillation, coined and rigorously analysed by Bravyi and Kitaev in 2004 and 2005, is the answer that has dominated the field for the last two decades [1]. The mindset is very similar to distilling alcohol from a weak mash: I start with many copies of a noisy non-stabilizer state, apply only Clifford operations and Pauli measurements, postselect on favourable measurement outcomes, and end up with fewer copies of a state that is closer to the ideal magic state.
In more operational terms I assume that my hardware can prepare some raw \(\rho\) that is close, but not extremely close, to \(\ket{T}\), say with an error rate \(p\) of order \(10^{-3}\) to \(10^{-2}\). I then choose a stabilizer code that admits a transversal \(T\) or related non-Clifford operation, and I use this code as an error-detecting filter. In each round of distillation I
- encode several copies of \(\rho\) into the code,
- measure the stabilizers to detect error syndromes, and
- condition on obtaining a trivial syndrome, i.e. I discard runs with detected errors.
When the syndrome is trivial, the postselected output state has an error probability that scales like a higher power of the input error, for example \(p_{\text{out}} \approx c\, p^{3}\) or \(p^{2}\) depending on the protocol. By iterating this procedure I can in principle drive the error arbitrarily low at the cost of consuming an increasing number of noisy inputs [1][3].
A Concrete Example: The Bravyi–Kitaev 5-Qubit Protocol
To make this less abstract, let me walk through the original Bravyi–Kitaev distillation routine for \(\ket{T}\) based on the \(\llbracket 5,1,3 \rrbracket\) code. This is historically important and also conceptually clean. The \(\llbracket 5,1,3 \rrbracket\) stabilizer code encodes one logical qubit into five physical qubits and has distance three. It is the smallest perfect quantum code, and, crucially for distillation, it has a transversal implementation of the \(T\) gate on the code space.
The protocol can be sketched as follows. I assume I can prepare five independent copies of a noisy \(\ket{T}\)-like state
where \(\sigma\) collects the orthogonal error component and \(p\) is small. I then:
- Apply the encoding circuit of the \(\llbracket 5,1,3 \rrbracket\) code to map the five physical qubits into one logical qubit plus four stabilizer degrees of freedom.
- Measure the four stabilizer generators. If I obtain the \(\ket{0000}\) syndrome I keep the state; otherwise I discard all qubits and restart.
- Apply the decoding circuit to extract a single physical qubit which, conditioned on the \(\ket{0000}\) syndrome, is now a higher-fidelity approximation to \(\ket{T}\).
A nice feature of this protocol is that the leading-order output error scales as
so for small \(p\) I obtain a quadratic suppression of the error at the cost of discarding runs with non-trivial syndrome [1]. Repeating the protocol recursively — feeding distilled states as input to the next round — yields a staircase-like flow on the Bloch sphere that converges towards the pure magic state.
Other protocols, for example those based on triorthogonal codes and higher-distance codes, achieve stronger suppression \(p_{\text{out}} \sim p^{k}\) with \(k > 2\) and better asymptotic yield parameters, at the cost of larger block sizes and more complex Clifford circuits [3]. The common pattern, however, is always the same: magic is not created from nothing, it is concentrated by sacrificing many slightly magical states to obtain a few highly magical ones.
Resource Overheads and the Distillation Factory Picture
When I move from toy protocols to full-scale fault-tolerant quantum algorithms, magic state distillation quickly becomes the dominant resource bottleneck. In the standard Clifford-plus-\(T\) paradigm, I express my logical circuit in terms of Clifford operations and \(T\) gates, then I design a distillation factory that produces high-fidelity \(\ket{T}\) states at a sufficient rate to feed those \(T\) gates. For surface code architectures this often leads to huge space-time costs: large patches of qubits running nested distillation routines for thousands of code cycles [2].
Multiple works over the last decade have optimised this factory picture. People have designed better codes, better scheduling, and more efficient layouts to reduce the number of physical qubits and the depth of distillation circuits. For instance, low-overflow triorthogonal constructions give a yield parameter \(\gamma\) close to the conjectured optimal value, where the required number of raw magic states scales like \(\log^{\gamma}(1/\epsilon)\) to achieve target error \(\epsilon\) [3]. Recent qutrit-based protocols even push these yields below what is known for comparable qubit codes [5].
Despite these advances, the fact remains that if I insist on arbitrarily low logical error rates solely through distillation, I pay substantial overheads. This is precisely the pain point that motivates exploring alternatives or complements to traditional distillation, such as magic state cultivation.
From Distillation to Cultivation: Changing the Mindset
Magic state cultivation is a relatively new proposal that reframes the problem. Instead of repeatedly applying a black-box distillation routine to many independent copies of a magic state, cultivation focuses on gradually improving the quality of a single magic state by growing the size and distance of the code that protects it. The image I like is that of nurturing a single fragile plant, rather than harvesting and processing an entire field at once[6].
The term cultivation has been popularised in recent work by Gidney and collaborators in the context of surface code architectures. The core idea is to integrate the whole procedure tightly with the code geometry: I start by injecting a noisy magic state into a small-distance patch, then I incrementally expand and stabilise this patch while repeatedly verifying the state using low-overhead Clifford checks native to the code. At each stage I either accept and continue growing, or I detect an error and restart the process. Crucially, the dominant operations are local checks within a single patch, which keeps the cost comparable to that of performing a logical CNOT gate of similar reliability [6].
Why Cultivation? Practical Motivations
Why should I bother with cultivation if I already have a whole zoo of distillation protocols? There are at least three practical motivations that resonate with me.
First, cultivation can dramatically reduce space-time overhead in the regime where I do not require astronomically small logical error rates. For realistic hardware noise levels on the order of \(10^{-3}\) to \(10^{-4}\), cultivation can reach output error rates in the ballpark of \(10^{-9}\) to \(10^{-11}\) using orders of magnitude fewer qubit-rounds than canonical factories [5][6]. This regime already covers many near-term fault-tolerant algorithms.
Second, cultivation fits naturally into the layout of a two-dimensional code. Rather than dedicating large regions exclusively to factories running complex codes with transversal \(T\), I can devote a modest patch that grows and shrinks as needed, interacting with data patches via standard lattice surgery moves. This kind of architectural co-design is crucial if I want to make the most of limited cryogenic real estate and routing complexity [4][5].
Third, cultivation responds very favourably to improvements in physical error rates. Because it is based on growing code distance and performing repeated checks, its logical error rate falls rapidly as hardware improves. This opens the door to hybrid schemes where cultivation provides almost all the required suppression, with at most a light final round of distillation to mop up the remaining errors [5][6].
Anatomy of a Cultivation Protocol
Let me now sketch the typical stages of a cultivation protocol as described in recent literature. Although implementations differ between surface codes and color codes, the broad structure is similar[6].
Stage 1: State Injection into a Small Code
I begin by injecting a raw magic state into a small-distance code, for example a distance-three color code patch or a tiny rotated surface code patch. Injection itself is a noisy process, often involving preparing an unencoded \(\ket{T}\) state on a physical qubit and then entangling it with the code via a sequence of CNOTs or lattice surgery moves. This step typically dominates the initial error contribution, since a single physical fault can corrupt the encoded state in a way that is hard to detect later [4].
Stage 2: Local Verification and Postselection
Once the state is encoded in a small patch, I exploit transversal or pieceable Clifford operations that are native to that code to verify consistency with the intended magic state. A typical pattern in color code cultivation is to perform a transversal Clifford that maps a correct \(\ket{T}\) to a stabilizer eigenstate, while mapping certain error patterns to orthogonal subspaces. By entangling the code with an ancilla Bell pair and performing phase kickback, I can detect whether the state is flawed without directly measuring it in the magic basis.
Operationally, I repeat a cycle of
- measuring all stabilizers of the small patch,
- performing a transversal Clifford designed to detect phase or amplitude errors specific to the magic axis,
- measuring an ancilla to infer a pass or fail condition.
If any of these checks fail, I discard the state and return to the injection step. If they pass, I move on to growing the code.
Stage 3: Growing the Code Distance
The cultivation name really earns its keep in this stage. I gradually grow the code by adding more physical qubits around the existing patch and turning on additional stabilizer measurements. In a surface code, this corresponds to expanding the patch boundaries and measuring more plaquettes; in a color code, it involves extending the lattice while maintaining the required coloring constraints[6].
During this growth phase I continue to perform repeated rounds of stabilizer measurements. The point is that as the code distance increases, the effective logical error rate associated with storage and Clifford manipulations of the magic state drops exponentially. I am therefore nurturing my magic state, protecting it more and more as it grows.
Stage 4: Approaching the Postselection Cost Wall
An important conceptual difference between cultivation and asymptotic distillation is that cultivation typically hits a practical floor in the error rate. Because each cultivation attempt involves postselection on many rounds of syndrome and verification checks, there is a point beyond which the acceptance probability becomes so small that the cost per successfully cultivated magic state blows up. This is sometimes referred to as the postselection cost wall[5].
In practice, this means cultivation is best used up to the point where the marginal gain in error suppression is still worth the incremental cost. Numerical studies show that for reasonable hardware error rates the sweet spot often lies around output infidelities of \(10^{-9}\) to \(10^{-11}\), beyond which it may be more efficient to hand over to one final round of conventional distillation if even lower errors are required [5][6].
A Simple Quantitative Picture
To get some intuition, I like to model cultivation as a two-parameter process characterised by
- an effective logical error rate \(p_{\text{L}}(d)\) that decays roughly like
\[ p_{\text{L}}(d) \approx A\, (c\, p)^{\lfloor (d+1)/2 \rfloor}, \]where \(p\) is the physical error rate, \(d\) is the code distance, and \(A, c\) are code-dependent constants;
- an acceptance probability \(q(d)\) that also decays with distance because more checks and more rounds provide more opportunities to detect an error and reject the attempt.
If each cultivation attempt to distance \(d\) costs me \(C(d)\) qubit-rounds and succeeds with probability \(q(d)\), then the expected cost per successfully cultivated magic state is roughly \(C(d)/q(d)\). The optimal cultivation depth balances the exponential drop in \(p_{\text{L}}(d)\) against the drop in \(q(d)\). Simulations in recent work suggest that this optimum lies at surprisingly modest distances, resulting in an overall resource cost comparable to a handful of logical CNOTs while achieving very low logical error rates [5][6].
Hybrid Architectures: Cultivation Feeding Distillation
Given that cultivation cannot realistically push errors to arbitrarily low values without hitting the postselection wall, whereas distillation can, an attractive architectural pattern is to combine the two. In such a hybrid scheme I would
- use cultivation to prepare medium-to-high-fidelity \(\ket{T}\) states at relatively low cost;
- feed these cultivated states into a small number of high-level distillation blocks, perhaps based on triorthogonal codes, to achieve the ultra-low error rates required by the largest logical circuits.
This strategy exploits the strengths of both paradigms: cultivation handles the heavy lifting of suppressing physical noise into the \(10^{-9}\) range using code growth and local checks, while distillation provides the final polishing step. Recent resource estimation work explicitly models such hybrid pipelines and finds substantial savings over pure distillation factories, especially when I factor in physical constraints like limited connectivity and realistic gate times [5].
Experimental Progress
Until recently, both distillation and cultivation lived largely in the world of numerical simulation and code-capacity thresholds. That is changing. Experimental groups have now demonstrated magic state distillation at the logical level on neutral-atom and superconducting platforms, using small-distance codes and modest block sizes to show that the hallmark error-suppression scaling can be observed in practice.
On the cultivation side, there are early demonstrations of color-code-based verification of \(\ket{T}\) states and surface code experiments that mimic some aspects of state growth and repeated verification. A recent report of magic state cultivation on a superconducting processor achieves roughly a forty-fold reduction in error, with final fidelities around \(0.9999\) while retaining a non-negligible fraction of attempts. As hardware improves, I expect this interplay between code design, distillation and cultivation to become one of the central themes in the engineering of large-scale quantum computers.
Concluding Thoughts
From my perspective as someone who spends a lot of time thinking about fault-tolerant architectures, magic state distillation and magic state cultivation feel less like competing paradigms and more like two sides of the same coin. Distillation taught us that non-Clifford resources can be tamed and concentrated using only Clifford operations and measurements. Cultivation reminds us that we should respect and exploit the geometry and dynamics of the underlying code, growing and protecting our magic much like a gardener tends a single plant.
I find it helpful to keep both pictures in mind when I design real-world architectures. For some algorithms and noise regimes, a classic distillation factory optimised with modern codes will be the right tool. For others, especially in the nearer term, cultivation-style protocols integrated into the code layout may well offer a faster and more frugal route to the magic we need.
Key References
- S. Bravyi and A. Kitaev, "Universal quantum computation with ideal Clifford gates and noisy ancillas," Phys. Rev. A 71, 022316 (2005).
- J. O'Gorman and E. T. Campbell, "Quantum computation with realistic magic state factories," Phys. Rev. A 95, 032338 (2017).
- E. Campbell, "Unified framework for magic state distillation and multiqubit gate synthesis with reduced resource cost," Phys. Rev. A 95, 022316 (2017), and related triorthogonal code constructions.
- D. Litinski, "A game of surface codes: Large-scale quantum computing with lattice surgery," Quantum 3, 128 (2019).
- S. Prakash and T. Saha, "Low-overhead qutrit magic state distillation," Quantum 9, 1768 (2025), and related resource estimation studies.
- C. Gidney, "Magic state cultivation: growing \(T\) states as cheap as CNOT," arXiv:2409.17595.